
자료구조의 정의
효율적인 프로그램을 작성할 때 가장 우선적인 고려사항은 저장 공간의 효율성과 실행시간의 신속성이다. 자료구조는 프로그램에서 사용하기 위한 자료를 기억장치의 공간 내에 저장하는 방법과 저장된 그룹 내에 존재하는 자료간의 관계, 처리방법등을 연구 분석하는 것을 말한다.
- 자료구조는 자료의 표현과 그것과 관련된 연산
- 일련의 자료들을 조직하고 구조화 하는것
- 어떤한 자료 구조에서도 필요한 모든 연산 처리 가능
- 자료 구조에 따라 프로그램 실행시간 달라짐
분류

1. 배열(Array)
동일한 자료형의 데이터들이 같은 크기로 나열되어 순서를 갖고있는 집합
- 정적인 자료 구조로 기억 장소의 추가가 어렵고, 데이터 삭제 시 기억 장소가 빈공간이 되어 메모리 낭비
- 반복적인 데이터 처리 작업에 적합
- 첨자를 이용하여 데이터에 접근하며, 첨자의 개수에 따라 n차원 배열이라고 함
- 데이터 마다 동일한 이름의 변수를 사용하여 처리 간편
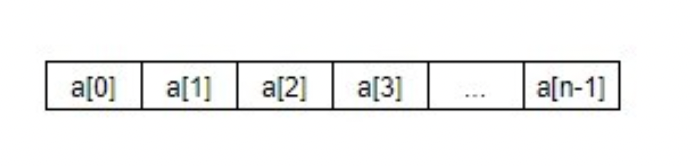
위 배열에서 '[숫자]' 가 첨자에 해당 a 는 변수이름
a[0] 부터 a[n-1] 까지 총 n개의 기억장소 존재

2개의 첨자가 존재하는 2차원 배열로, n*n 개의 기억장소 존재
2. 선형 리스트(Linear List)
일정한 순서에 의해 나열된 자료 구조로, 배열을 이용하는 연속 리스트(Contiguous List)와 포인터를 이용하는 연결리스트(Linked List)로 구분
연속 리스트(Contiguous List)
- 배열과 같이 연속되는 기억장소에 저장되는 자료 구조
- 기억장소를 연속적으로 배정받기 때문에 기억장소 이용 효율은 밀도가 1로서(꽉차게 사용한다는것) 가장 좋다
- 중간에 데이터 삽입 위해서는 연속된 빈 공간 있어야하며 , 삽입 삭제시 자료의 이동 필요

연결 리스트(Linked List)
자료들을 반드시 연속적으로 배정시키지 않고 임의의 기억공간에 배치 시키되, 순서에 따라 노드의 포인터 부분을 이용하여 서로연결한 구조
- 노드의 삽입/삭제 용이
- 기억공간이 연속적으로 놓여 있지않아도 저장 가능
- 연결을 위한 링크(포인터) 부분이 필요해서 순차 리스트에 비해 효율이 좋지 않다
- 포인터를 찾는 시간으로 인해 접근 속도 느림
- 중간 노드 끊어지면 다음 노드 찾기 어려움

3. 스택(Stack)
리스트의 한쪽 끝으로만 자료의 삽입, 삭제 이루어 지는 구조
- 후입선출(LIFO; Last In First Out)
- 재귀 호출, 후위(Postfix) 표기법, 서브루틴 호출, 인터럽트 처리, 깊이 우선 탐색 등에 사용
- 모든 기억 공간 꽉 찬 상태에서 사용하면 오버플로(Overflow) 발생, 삭제 할것 없는 상태에서 삭제하면 언더플로(Underflow) 발생

- TOP: 가장 마지막으로 삽입된 공간 위치
- Bottom: 바닥
- Push: 자료의 삽입
- Pop Up: 자료의 삭제
4. 큐(Queue)
한쪽에서는 삽입, 한쪽에서는 삭제 작업 이루어 지는 자료 구조
- 선입선출(FIFO; First In First Out) 구조
- 시작과 끝을 표시하는 두개의 포인터
- 운영체제의 작업 스케줄링에 사용

- 프런트(F, Front) 포인터 : 가장 먼저 삽입된 자료 공간 가리킴. 삭제 작업에 사용
- 리어(R, Rear) 포인터 : 가장 나중 공간 가리킴. 삽입 작업에 사용
5. 그래프(Graph)
그래프 G 는 정점 V(Vertex)와 간선 E(Edge)의 두집합으로 이루어진다.
- 간선의 방향성 유무에 따라 방향, 무방향 그래프로 구분
- 통신망, 교통망, 이항 관계, 연립방정식, 유기화학 구조식, 무향선분 해법 등에 사용
- 트리(Tree)는 사이클이 없는 그래프

6. 트리(Tree)
정점(Node, 노드)과 선분(Branch, 가지)을 이용하여 사이클을 이루지 않도록 구성한 그래프
- 하나의 기억공간을 노드(Node)라고 하며, 노드와 노드를 연결하는 선을 링크(Link)라고 함
- 가족의 계보(족보), 조직도 등을 표현하기에 적합

- Node : 자료 항목과 다른 항목에 대한 가지(Branch) 를 합친 것
- Root Node : 맨 위의 노드
- Degree : 각 노드에서 뻗어나온 가지의 수
- Terminal Node = Leaf Node : 자식이 하나도 없는 노드 (Degree = 0)
- Son Node : 어떤 노드에 연결된 다음 노드들
- Parent Node : 이전 레벨의 노드들
- Borther Node, Sibling : 동일한 부모를 갖는 노드들
- 트리의 디그리 : 노드 중 가장 높은 디그리의 수치
트리의 운행법(Traversal)
트리를 구성하는 각 노드들을 찾아가는 방법
- Preorder 운행 : Root - Left - Right
- Inorder 운행 : Left - Root - Right
- Postorder 운행 : Left - Right - Root
수식의 표기법
산술식을 계산하기 위해 기억공간에 기억시키는 방법으로, 이지트리 많이 사용. 이진트리로 만들어진 수식을 인오더, 프리오더, 포스트 오더로 운행하면 각각 중위(Infix), 전위(Prefix), 후위(Postfix) 표기법
- 전위 표기법(PreFix) : 연산자 - Left - Right
- 중위 표기법(InFix) : Left - 연산자 - Right
- 후위 표기법(PostFix) : Left - Right - 연산자
InFix 에서 표기법 변경하기
예) X = A/B * (C+D) + E
- Prefix 로 변환
➀ 우선순위 대로 괄호로 묶는다
(X = (((A/B) * (C+D)) + E ))
➁ 연산자를 괄호 앞으로 옮김
결과 : =X+*/AB+CDE
-Postfix 는 반대로 괄호 뒤로 옮기면 됨
결과 : XAB/CD+*E+=
Postfix 또는 Prefix 에서 InFix로 변경하기
- Postfix에서 Infix
예) ABC-/DEF+*+
➀ Postfix는 연산자가 피연산자 두개 뒤로 이동한 것이므로 피연산자 두개씩 괄호로 묶는다.
((A(BC-)/)(D(EF+)*)+)
➁ 피연산자 가운데로 이동
A/(B-C)+D*(E+F)
- Prefix에서 Infix
예) +/A-BC*D+EF
➀ Prefix는 연산자가 피연산자 두개 앞으로 이동한 것이므로 피연산자 두개씩 괄호로 묶는다.
(+(/A(-BC))(*D(+EF)))
➁ 피연산자 가운데로 이동
A/(B-C)+D*(E+F)
정렬(Sort)
1. 삽입 정렬(Insertion Sort)
- 가장 간단한 정렬방식
- n번째 키를 앞의 n-1개의 키와 비교하여 정렬한다
- 평균, 최악 모두 시간복잡도는 O(n^2)

2. 쉘 정렬(Shell Sort)
- 삽입정렬을 확장한 개념
- 입력 파일이 부분적으로 정렬되어 있는 경우 유리
- 초기 간격을 임의의 값으로 정하고, 나누어서 서브 파일을 구성한다(서브 리스트) 구성된 서브 파일 내에서 삽입 정렬 수행, 임의값을 변경하여 반복
- 초기값을 n/2 로 설정하고, 간격이 홀수가 나오는것이 유리하기 때문에 짝수일 경우 +1 을 해준다
- 평균 수행 시간 복잡도 O(n^1.5)
- 최악 수행 시간 복잡도 O(n^2)

3. 선택 정렬(Selection Sort)
- n개의 레코드중 최소값을 찾아 첫번째에 놓는것을 반복
- 평균, 최악 시간 복잡도 O(n^2)
4. 버블 정렬(Bubble Sort)
- 인접한 두개의 레코드 값 비교하여 변경하는것을 반복
- 평균, 최악 시간 복잡도 O(n^2)
5. 퀵 정렬(Quick Sort)
하나의 파일을 부분적으로 나누어 가면서 키(Pivot)를 기준으로 작은 값은 왼쪽, 큰값은 오른쪽 서브파일로 분해하고, 더이상 나눌 수 없을때까지 반복
- 위치에 상관없이 임의의 키를 분할원소로 사용 가능
- 정렬 방식 중 가장 빠름
- 스택(Stack) 필요
- 분할(Divide) 과 정복(Conquer) 방식 사용
- 평균 수행 시간 복잡도 O(nlog₂n) 최악 O(n^2)

6. 힙 정렬
전이진 트리(Complete Binary Tree)를 사용한 정렬 방식
구성된 전이진 트리를 Heap Tree 로 변환하여 정렬
평균, 최악 모두 O(nlog₂n)

7. 2-Way 합병 정렬(Merge Sort)
이미 정렬되어 있는 두 개의 파일을 한 개의 파일로 합병하는 방식
- 두 개의 키들을 한 쌍으로 하여 각 쌍에 대해 순서를 정하고, 순서대로 정렬된 각 쌍의 키들을 합병하여 하나의 정렬된 서브리스트로 만든다. 이것을 하나의 정렬된 파일이 될 때까지 반복한다,
- 평균과 최악 모두 시간 복잡도 O(nlog₂n)

8. 기수 정렬(Radix Sort) = Bucket Sort
Queue 를 이용하여 자릿수(Digit)별로 정렬하는 방식
- 레코드 키값을 똑같은 문자 또는 같은 수 끼리 순서에 맞는 버킷에 분배하였다가 버킷 순서대로 레코드 꺼내어 정렬
- 평균과 최악 모두 O(dn)

- 첫번째는 1의 자리수, 두번째는 10의 자리수 정렬
출처
자료 참고:
시나공 정보처리기사 필기 2022를 참고하여 작성되었습니다

[1] 자료구조 https://m.blog.naver.com/limje1623/221842023446
[2] 자료구조 https://www.zerocho.com/category/Algorithm/post/584b9033580277001862f16c
[3] 삽입정렬 https://itstory.tk/entry/%EC%82%BD%EC%9E%85%EC%A0%95%EB%A0%ACInsertion-Sort
[4] 쉘 정렬 https://gmlwjd9405.github.io/2018/05/08/algorithm-shell-sort.html
[5] 퀵 정렬 https://gmlwjd9405.github.io/2018/05/10/algorithm-quick-sort.html
[6] 힙 정렬 https://gmlwjd9405.github.io/2018/05/10/algorithm-heap-sort.html
[8] 기수 정렬 https://sticky32.tistory.com/entry/Radix-Sort-%EA%B8%B0%EC%88%98-%EC%A0%95%EB%A0%AC
'정보처리기사 > 2과목' 카테고리의 다른 글
| [정보처리기사 필기] 인터페이스 구현 (0) | 2022.02.13 |
|---|---|
| [정보처리기사 필기] 애플리케이션 테스트 관리, 복잡도 (0) | 2022.02.13 |
| [정보처리기사 필기] 제품 소프트웨어 패키징 (0) | 2022.02.11 |
| [정보처리기사 필기] 통합 구현 (0) | 2022.02.11 |
| [정보처리기사 필기] 데이터베이스, 데이터 입출력 용어 정리 (0) | 2022.02.10 |



댓글